Пособие по практике программирования
с расчетом на эффективную работу,
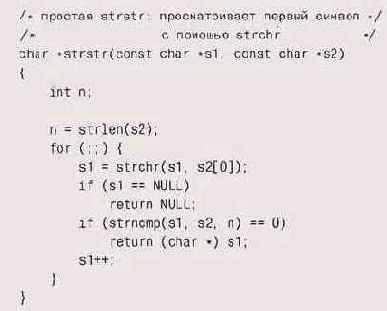
Функция была написана с расчетом на эффективную работу, и действительно, для типичных случаев использования этот код оказывался достаточно быстрым, поскольку в нем используются хорошо оптимизированные библиотечные функции. Сначала вызывается st rch r для поиска следующего вхождения первого символа образца, а затем strncmp — для проверки, совпадают ли остальные символы строки с остальными символами образца. Таким образом, изрядная часть сообщения пропускалась — до первого символа образца, и проверка начиналась только с него. Почему же возникли проблемы с производительностью?
На это есть несколько причин. Во-первых, strncmp получает в качестве аргумента длину образца, которая должна быть вычислена с помощью st rlen. Однако длина образца у нас фиксирована, так что нет необходимости вычислять ее заново для каждого сообщения.
Во-вторых, strncmp содержит достаточно сложный внутренний цикл. В нем не только осуществляется сравнение байтов двух строк, но и производится поиск символа окончания строки \0 в обеих строках, да еще при этом отсчитывается длина строки, переданной в качестве параметра. Поскольку длина всех строк известна заранее (хотя и не в функции st rncmp), в этих сложностях нет необходимости, мы знаем, что подсчеты верны, поэтому проверка на \0 — пустая трата времени.
В-третьих, strchr также сложна, поскольку она должна просматривать символы и при этом отслеживать \0, завершающий строку. При каждом конкретном вызове isspam сообщение фиксировано, поэтому время, использованное на поиск \0, опять же тратится зря, так как мы знаем, где окончится сообщение.
И наконец, даже если решить, что strncrnp, strchr и strlen достаточно эффективны сами по себе, затраты на вызов этих функций сравнимы с затратами на вычисления, которые они осуществляют. Более эффективно выполнять все действия в отдельной аккуратно написанной версии st rst r, а не вызывать другие функции.
Трудности подобного рода — обычный источник проблем с производительностью: функция или интерфейс хорошо работают в обычных ситуациях, но недостаточно производительны для нестандартного случая, а именно этот случай и является основным для решаемой задачи.
