Пособие по практике программирования
В вычислениях символы принимаются неотрицательными
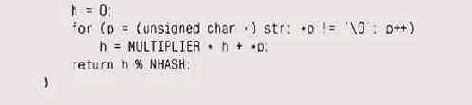
В вычислениях символы принимаются неотрицательными принудительно (тем, что используется тип unsigned char), так как ни в С, ни в C++ наличие знака у символов не регламентировано, а мы хотим, чтобы наша хэш-функция оставалась положительной.
Хэш-функция возвращает результат по модулю размера массива. Если хэш-функция распределяет данные равномерно, то точный размер массива неважен. Трудно, однако, гарантировать, что хэш-функция независима от размера массива, и даже у хорошей функции могут быть проблемы с некоторыми наборами входных данных. Поэтому имеет смысл сделать размер массива простым числом, чтобы слегка подстраховаться, обеспечив отсутствие общих делителей у размера массива, хэш-мультипликатора и, возможно, значений данных.
Эксперименты показывают, что для большого числа разных строк трудно придумать хэш-функцию, которая работала бы гораздо лучше, чем эта, зато легко придумать такую, которая работает хуже. В ранних версиях Java была хэш-функция для строк, работавшая более эффективно, если строка была длинной. Хэш-функция работала быстрее, анализируя только 8 или 9 символов через равные интервалы в строках длиннее, чем 16 символов, начиная с первого символа. К сожалению, хотя хэш-функция работала быстрее, у нее были очень плохие статистические показатели, что сводило на нет выигрыш в производительности. Пропуская части строки, она нередко выкидывала именно различающиеся части строк. Имена файлов начинаются с длинных идентичных префиксов — имен каталогов — и могут отличаться только несколькими последними символами (например, .Java и .class). Адреса в Internet обычно начинаются с http://www. и заканчиваются на . html, поэтому все различия у них в середине. Хэш-функция частенько проходила только по неразличающейся части в имени, в результате чего образовывались более длинные хэш-цепочки, что замедляло поиск. Проблема была решена заменой хэш-функции на эквивалентную той, что мы привели выше (с мультипликатором 37), которая исследует каждый символ в строке.
Хэш-функция, которая неплохо подходит для одного набора данных (например, имен переменных), может плохо подходить для другого (адреса Internet), так что потенциальная хэш-функция должна быть протестирована на разных наборах типичных входных данных.
